
Here's an axiom for every major organization to memorize: if you have data, then you have a data storage problem. But while the cloud service players are happy to compete for your business, you may not need to purchase a solution. A number of open source projects offer flexible ways to build your own distributed, fault-tolerant storage network. This weekend, let's take a look at one of the most intriguing offerings: Tahoe LAFS.
Tahoe is a "Least Authority File System" — the LAFS you often see in concert with its name. The LAFS design is an homage to the security world's "principle of least privilege": simply put, Tahoe uses cryptography and access control to protect access to your data. Specifically, the host OS on a Tahoe node never has read or write access to any of the data it stores: only authenticated clients can collect and assemble the correct chunks from across the distributed nodes, and decrypt the files.
Beyond that, though, Tahoe offers peer-to-peer distributed data storage with adjustable levels of redundancy. You can tune your "grid" for performance, fault-tolerance, or strike a balance in between, and you can use heterogeneous hardware and service providers to make up your nodes, providing you with a second layer of protection. Furthermore, although you can use Tahoe-LAFS as a simple distributed filesystem, you can also run web and (S)FTP services directly from your Tahoe grid.
Installation and TestingThe most recent Tahoe release is version 1.9.1, from January 2012. The project provides tarballs for download only, but many Linux distributions now offer the package as well, so check with your package management system first. Tahoe is written in Python, and uses the Twisted framework, as well as an assortment of auxiliary Python libraries (for cryptography and other functions). None are particularly unusual, but if you are installing from source, be sure to double check your dependencies.
Once you have unpacked the source package, execute python ./setup.py build to generate the Tahoe command line tools, then run python ./setup.py test to run the installer's sanity check suite. I found that the Ubuntu package failed to install python-mock, but Tahoe's error messages caught that mistake and allowed me to install the correct library without any additional trouble.
Now that you have the Tahoe tools built, you can connect to the public test grid to get a feel for how the storage system works. This grid is maintained by the project, and is variously referred to as pubgrid or Test Grid. You can experiment with the Tahoe client apps on pubgrid — however, because it is a testbed only, its uptime is not guaranteed, and the maintainers may periodically wipe and rebuild it.
First, run tahoe create-client. This creates a local client-only node on your machine (meaning that it does not offer storage space to the grid), which you will connect to pubgrid by editing the configuration file in ~/.tahoe/tahoe.cfg. Open the tahoe.cfg file and edit the nickname = and introducer.furl = lines.
The nickname is any moniker you choose for your node. During this testing phase, the name makes no difference, but when deploying a grid, useful names can help you keep better tabs on your nodes' performance and uptime. The "introducer" is Tahoe lingo for the manager node that oversees a grid — keeping track of the participating nodes in a publish/subscribe "hub" fashion. The pubgrid's current "FURL" address is pb://tin57bdenwkigkujmh6rwgztcoh7ya7t@pubgrid.tahoe-lafs.org:50528/introducer — but check the Tahoe wiki before entering it in the configuration file, in case it has changed.
Save your configuration file, then run ./tahoe start at the command line. You're now connected! By default, Tahoe offers a web-based interface running at http://127.0.0.1:3456 ... open that address in your web browser, and you will see both a status page for pubgrid (including the grid IDs of nearby peers), and the controls you need to create your own directories and upload test files.
File Storage and Other Front-EndsPart of Tahoe's LAFS security model is that the directories owned by other nodes are not searchable or discoverable. When you create a directory (on pubgrid or on any other grid), a unique pseudorandom identifier is generated that you must bookmark or scrawl down someplace where you won't forget it. The project has created a shared public directory on pubgrid at this long, unwieldy URI, which gives you an idea of the hash function used.
You can add directories or files in the shared public directory, or create new directories and upload files of your own. But whenever you do, it is up to you to keep track of the URIs Tahoe generates. You can share Tahoe files with other users by sending them the URIs directly. Note also that whenever you upload a file, you have the option to check a box labeled "mutable." This is another security feature: files created as immutable are write-protected, and can never be altered.
In the default setup, your client-only node is not contributing any local disk space to the grid's shared pool. That setting is controlled in the [storage] stanza of the tahoe.cfg file. Bear in mind that the objects stored on your contribution to the shared pool are encrypted chunks of files from around the grid; you will not be able to inspect their contents. For a public grid, that is something worth thinking about, although when running a grid for your own business or project, it is less of a concern.
If all you need to do store static content and be assured that it is securely replicated off-site, then the default configuration as used by pubgrid may be all that you need. Obviously, you will want to run your own storage nodes, connected through your own introducer — but the vanilla file and directory structure as exposed through the web GUI will suffice. There are other options, however.
Tahoe includes REST API in tandem to the human-accessible web front-end. This allows you to use a Tahoe LAFS grid as the storage engine to a web server. The API exposes standard GET, PUT, POST, and DELETE methods, and supports JSON and HTML output. The API is customized to make Tahoe's long, human-unreadable URIs easier to work with, and provides utilities to more easily work with operations (such as search) than can take longer on a distributed grid than they would on a static HTTP server.
There is also an FTP-like front-end, which support SSL-encrypted SFTP operations, and a command-line client useful for server environments or remote grid administration. Finally, a "drop upload" option is available in the latest builds, which allows Tahoe to monitor an upload directory, and automatically copy any new files into the grid.
Running Your Own GridThe pubgrid is certainly a useful resource for exploring how Tahoe and its various front-ends function, but for any real benefit you need to deploy your own grid. Designing a grid is a matter of planning for the number of storage nodes you will need, determining how to tune the encoding parameters for speed and redundancy, and configuring the special nodes that manage logging, metadata, and other helper utilities.
The storage encoding parameters include shares.needed, shares.total, and shares.happy (all of which are configurable in the tahoe.cfg file). A file uploaded to the grid is divided into shares.needed chunks, to be distributed across the nodes. Tahoe will replicate a total of shares.total chunks, so total must be greater-than-or-equal-to needed. If they are equal, there is no redundancy.
The third parameter, shares.happy, defines the minimum number of nodes the chunks of any individual file must be spread across. Setting this value too low sacrifices the benefits of redundancy. By default, Tahoe is designed to be tolerant of nodes whose availability comes and goes, not only to cope with failure, but to allow for a truly distributed design where some nodes can be disconnected and not damage the grid as a whole. There is a lot to consider when designing your grid parameters; a good introduction to the trade-offs is hosted on the project's wiki.
You can run services — such as the (S)FTP and HTTP front-ends discussed above — on any storage node. But you will also need at least one special node, the introducer node required for clients to make an initial connection to the grid. Introducers maintain a state table keeping track of the nodes in a grid; they look for basic configuration in the [node] section of tahoe.cfg, but ignore all other directives.
To start yours, create a separate directory for it (say, .tahoe-my-introducer/, change into the directory, and run tahoe create-introducer . followed by tahoe start .. When launched, the new introducer creates a file named introducer.furl; this holds the "FURL" address that you must paste into the configuration file on all of your other nodes.
You can also (optionally) create helper, key-generator, and stats-gatherer nodes for your grid, to offload some common tasks onto separate machines. A helper node simply assists the chunk replication process, which can be slow if many duplicate chunks are required. You can designate a node as a helper by setting enabled = true under the [helper] stanza in tahoe.cfg.
The setup process key-generators and stats-gatherers is akin to that for introducers: run tahoe create-key-generator . or tahoe create-stats-gatherer . in a separate directory, followed by tahoe start .. Stats gatherers are responsible for logging and maintaining data on the grid, while key generators simply speed up the computationally-expensive process of creating cryptographic tokens. Neither is required, but using them can improve performance.
Setting up a Tahoe LAFS grid to serve your company or project is not a step to be taken lightly — you need to consider the maintenance requirements as well as how the competing speed and security features add up for your use case. But the process is simple enough that you can undertake it in just a few days, and even run multi-node experiments, all with a minimum of fuss.
]]>


 A lot of people have rather negative attitudes towards accessible design, and dismiss it as a lot of bother for a tiny percentage of users. Some are even hostile to the whole concept, like it's conferring special privileges on the undeserving. I had a rather spirited discussion with a building contractor once upon a time who went out of his way to park his equipment on the handicap parking spaces when there was abundant regular parking closer to the work site. (The older I get the less I understand humanity.)
A lot of people have rather negative attitudes towards accessible design, and dismiss it as a lot of bother for a tiny percentage of users. Some are even hostile to the whole concept, like it's conferring special privileges on the undeserving. I had a rather spirited discussion with a building contractor once upon a time who went out of his way to park his equipment on the handicap parking spaces when there was abundant regular parking closer to the work site. (The older I get the less I understand humanity.) Of course the first result most folks will want to know about is the favorite desktop distribution. Once again, Ubuntu has taken the crown, though not quite as handily as last year.
Of course the first result most folks will want to know about is the favorite desktop distribution. Once again, Ubuntu has taken the crown, though not quite as handily as last year. 
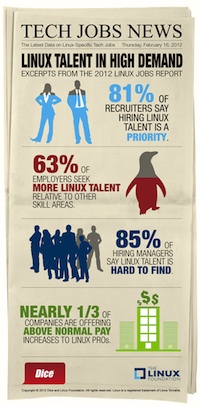 The first-ever
The first-ever 